AI screenshot renamer with ollama LLaVA, GPT-4o and macOS OCR
Contents
Last week Microsoft had to deal with some criticism, because they announced “Recall”, a new feature, available only on their new Copilot+ AI-enabled laptops, that makes regular screenshots as the computer is used and uses on-device models to generate descriptions of these images that can be stored in a database (sqlite of course) and later searched, so that a user can effectively go back in time to find almost anything. They have stated that everything happens and is stored on-device, and that the whole feature can be easily disabled.
To me this sounded like a neat feature, but the internet positively exploded with outrage.
The critics say that this is a privacy nightmare, because if someone gains access to your device, they gain access to a whole lot of potentially private information.
That is certainly a substantial risk, and it should be managed well, but personally I’m not comfortable with preventing other customers from getting access to such a useful feature.
(It is interesting to compare this new functionality with automatic backup systems like Time Machine or File History which continuously and automatically back up everything on your device, and also enable you to go back in time to view any of your files at any point.)
Whatever the case may be, I’m still rocking previous generation technology (MacBook Pro M1 something something), but I really do make a tonne of screenshots (manually, and out of my own free will), and I’ve often thought that it would be cool to use one of these new new vision language models (VLM) like llava or even GPT-4o to analyze the image contents and suggest a nice descriptive name for the screenshot.
This post documents how I got all of that working during some hours of weekend hobby time. I’m also making available my implementation so that you can try it for yourself.
An example
Below is as screenshot I chose from my screenshots folder for this demonstration. Most of them are a bit more serious and work-related than this.
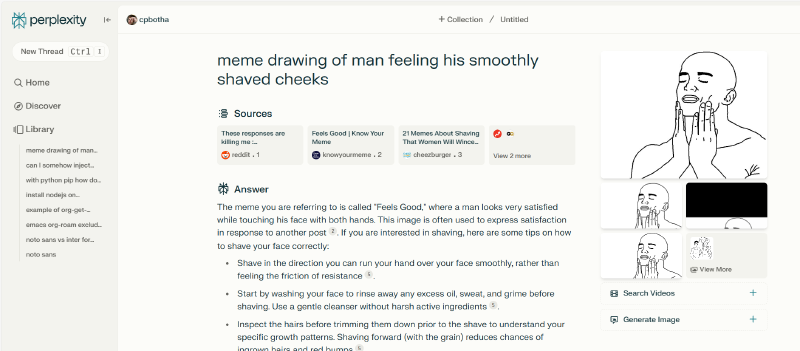
Figure 1: Screenshot of perplexity session during which I learned that the name of the meme is in fact “feels good”
When I run the script with this screenshot path as argument, it sends the image along with the macOS-extracted text to the configured llava-phi3 model running locally, and then suggests a new more descriptive name:
|
|
By default, it will only show you what it suggests, but you can add the --do-rename option to instruct it to actually rename the file on disk.
Although it’s often not what I would have come up with, the suggestions definitely improve the searchability of the filenames, and it’s hard to resist the ease of this automation.
Show me the code
You can get the Python source code for the ai-image-namer CLI from the ai-screenshot-namer github. The README there explains how to get everything running.
By browsing the code, you’ll learn about:
- Using macOS shortcuts to extract text from images, which we use to help the poor AI.
- Using ollama for local serving of the llava 1.6 (also known as llava-next) vision language model.
- Using GPT-4o with multi-modal messages when you want the highest quality results, or you can’t be bothered getting ollama running.
- Bundling this functionality in a self-documenting Python CLI using the wonderful click package.
- Making a utility such as this pipx-installable is close to zero-effort, and great for users who just want to try it out.
In the following sections, I go into a bit more detail on some elements of this fun project.
What is LLaVA?
A vision language model, or VLM, is a model that takes both text and images as input, and can then answer questions about the supplied images and text.
LLaVA is a small and simple sort of VLM that gives surprisingly good results for its size.
As you can see from the figure below, reproduced from the paper Improved Baselines with Visual Instruction Tuning (joint work between University of Wisconsin-Madison and… Microsoft Research) that introduced LLava 1.5, it works by encoding the input images as vectors using the CLIP ViT-L/336px model that was introduced by OpenAI, and then learning to project those into the same embedding space via multi-layer perceptron (aka MLP, in this case 2 layers if I understand correctly) as the tokenized text inputs so that they can be processed by the integrated language model in a unified fashion along with that text.
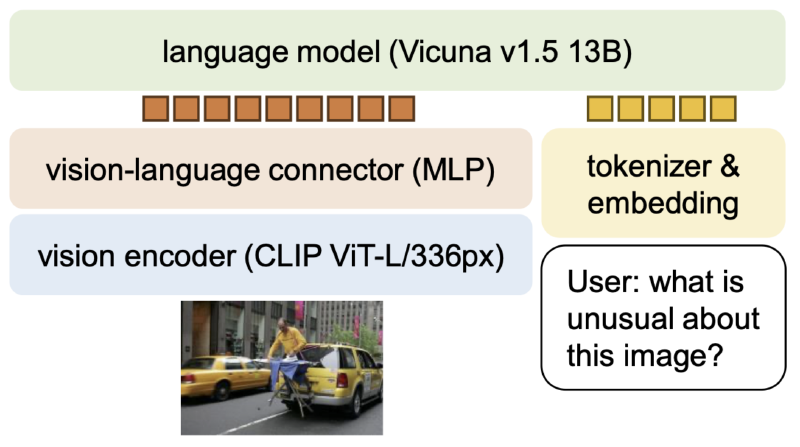
In the LLaVa-NeXT (aka 1.6) follow-up work, they extend LLaVA with support for higher resolution input images (by chopping up the input image into up to four patches, and submitting those patches along with a downsampled version of the full original for context), with more training data, and with support for additional and larger LLM backbone choices, such as Mistral and Nous-Hermes-2-Yi.
ollama
Ollama is a great open source tool with which you can be up and running with local LLMs in a few minutes!
Download and install from the website, pull a model with e.g. ollama pull llava and then test with ollama run llava-phi3 which will give you a console chat interface. You now have a locally running AI, whoo!
Usually you’ll use ollama start to expose a locally running API server that can be contacted by apps such as the ai-screenshot-namer
macOS shortcut for command-line extraction of text from images
Because a number of my test screenshots seemed to pose quite a challenge for llava:13b-v1.6 (and it’s resolution can be limited), I decided to look into how I could use the macOS built-in image OCR to add the text to the image prompt as well.
Today I learned that macOS has a built-in shortcuts command with which Shortcuts can be invoked, and so I only had to figure out if I could get images loaded and text output to the command-line as well.
After an acceptable amount of sweat and a bit of teeth gnashing, I was able to construct this shortcut:
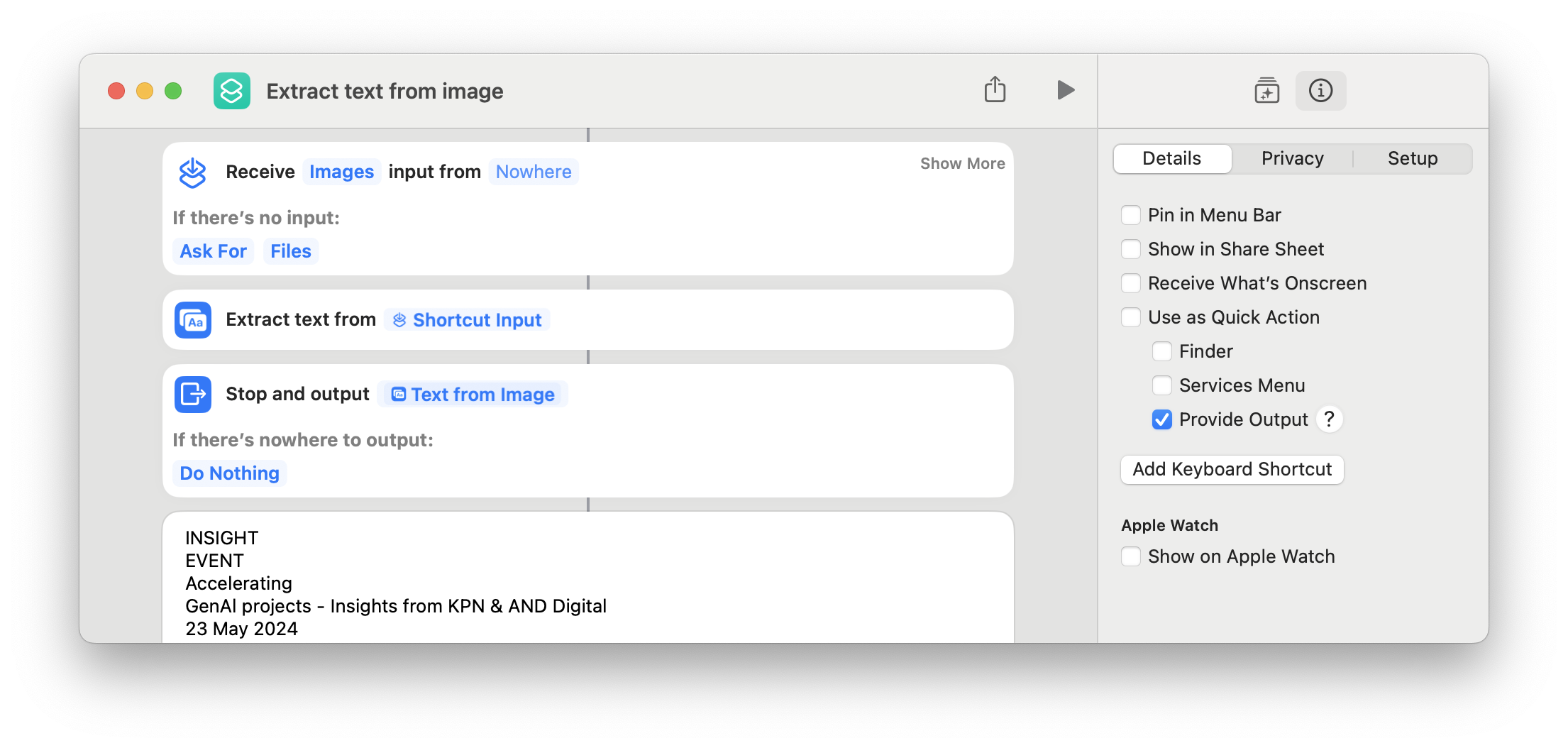 … which I can invoke from the command-line like this:
… which I can invoke from the command-line like this:
|
|
You can try and reproduce the shortcut on your side based on the screenshot above, or you can just download mine.
Even if your system is not macOS, the code will still work, it will just have to rely on the VLM’s image understanding alone.
Discussion
It was fun to put this demo together. I enjoyed combining the different elements, and I was especially happy with how easy it has become to run local models with tools like ollama.
Below is the prompt that is currently used to convince the model to give usable filename suggestions:
Suggest a lowercase filename of up to 64 characters (up to 10 words) for the included image (a screenshot) that is descriptive and useful for search. Return ONLY the suggested filename. It should be lowercase and contain only letters, numbers, and underscores, with no extension.
It should follow the form main-thing_sub-thing_sub-thing etc. Some good examples of filenames are: “slide_sql_datagrid” OR “screenshot_python_datetime_conversion” OR “dashboard_sensor_graphs” OR “email_godaddy_domain_offer” OR “tweet_meme_ai_vs_ml”
In addition to the image itself, I include at the end of this message any text that appears in the image to help you come up with a good name. Text from image: <THE EXTRACTED TEXT>
If you just specify “describe the image” you get a pretty detailed textual description. One could use a different prompt, requesting the model to give more structured output, along with a structured output generation library such as outlines to guarantee the generation of e.g. json according to some schema of your design. Outputs would then be more amenable to storage in a database for more predictable querying at a later stage. That is probably closer to what Microsoft has put together with Recall.
Whatever the case may be, it’s quite funny that this sort of human-style communication (coaxing?), embedded in between the more conventional programming language, is steadily becoming par for the course of modern software system construction.